Hadoop Ecosystem
Hadoop
When we talk about big data, we often think of Hadoop. Why? Hadoop is a system for storing data, processing data and managing data. It can ingest data from different platform or resources. In the big data world, sometimes, the traditional DBMSs could not meet their reporting requirements. Companies may require to shorten the time to process a significant amount of data. Increasing more storage or computer power could be another benefit using Hadoop.
Hadoop consists of three basic parts:
- HDFS: storing data
- YARN: managing data
- MapReduce: processing data
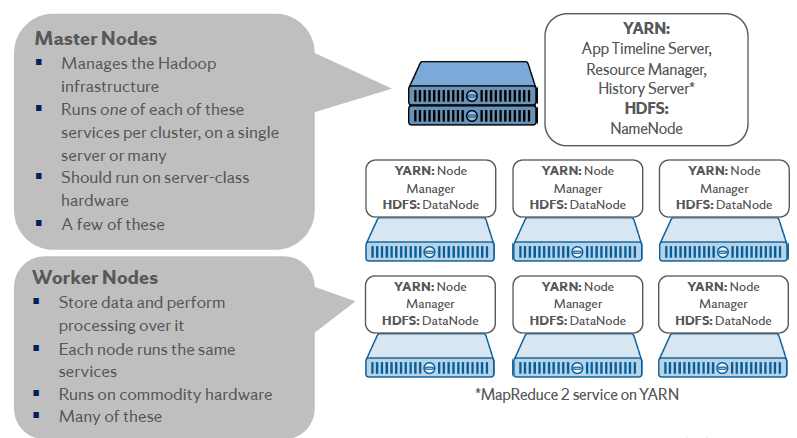
Hadoop implements cluster management in the system. It stores data and process data in clusters. Each cluster contains a master node and worker nodes. The master node runs the Apache Yarn as Resource Manager. The worker node runs Apache Yarn as Node Manager to getting the information of CPU, memory, disk and network usage to the Resource Manager. The Resource Manager decides where to direct the new tasks based on the current workloads reported from Node Manager with the Scheduler and ApplicationsManager.
Hadoop Data are:
- Time-variant: reflect that point in time
- Non-volatile: not updated
- Subject-oriented: stored by topic
The example of hadoop data are web logs, sales transactions, event records, sensor data…etc
The Hadoop Philosophy
- Capture the data “as are” and store them.
- Do not transform before you store them.
- Store all the data, as you don’t know what you’ll need.
- Transform them when you query them.
This is the anti-pattern of relational modeling!
How Does Hadoop Differ From Relational?
| Relational | Hadoop |
|---|---|
|
|
Note: ACID (Atomicity, Consistency, Isolation, Durability)
MapReduce
MapReduce is a processing technique and a program model for distributed computing based on java. Map takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs).
- Map: apply a transformation to a data set
- Shuffle: transfer output from Mapper to Reducer nodes
- Reduce: aggregate items into a single result
- Combine: output of Reducer nodes into single output
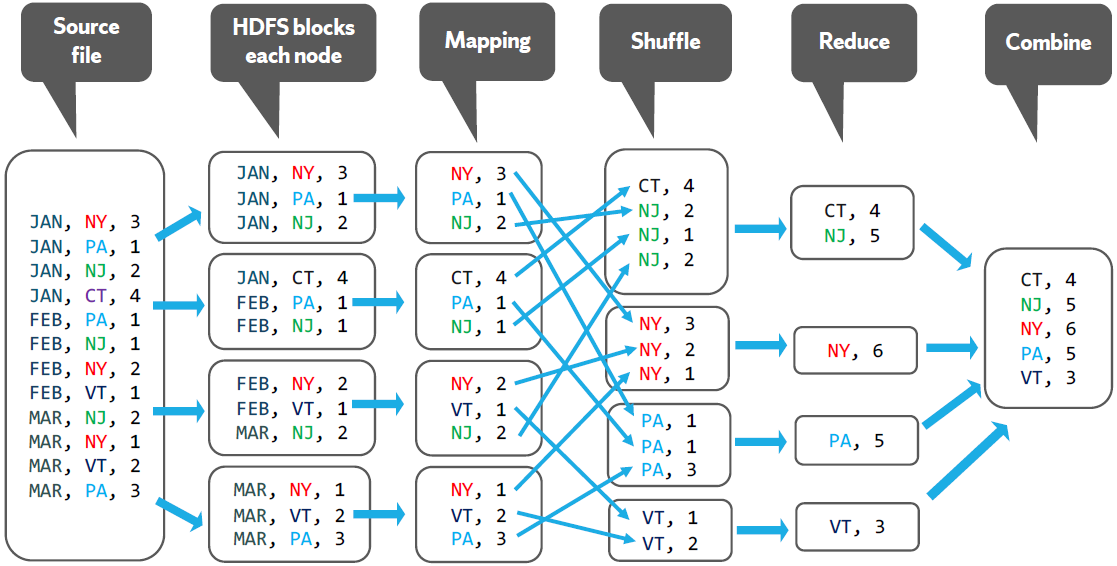
MapReduce process
HDFS
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets.
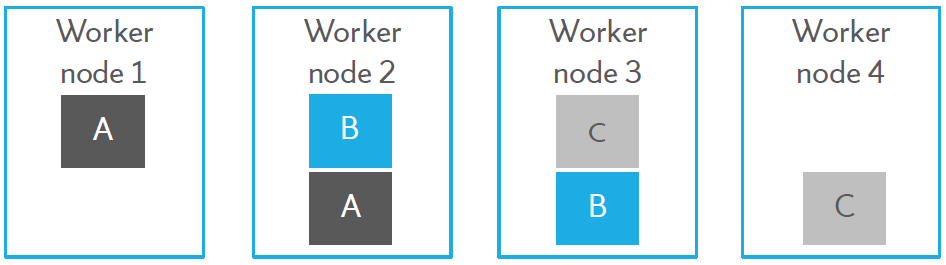
HDFS is reponsible for:
- Distributed data storage paradigm
- A single file is divided into blocks
- Blocks are spread across nodes
- Blocks are written multiple times for redundancy

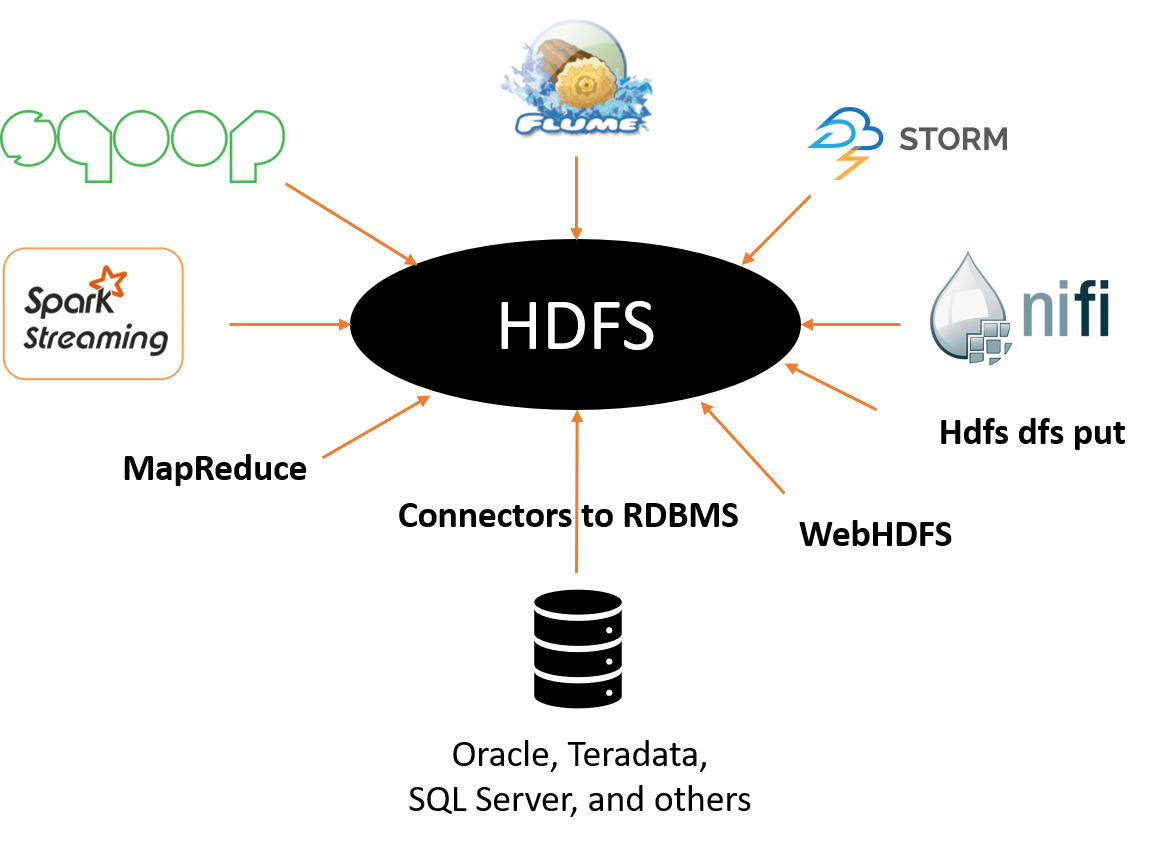
Hadoop Ecosystem in Action
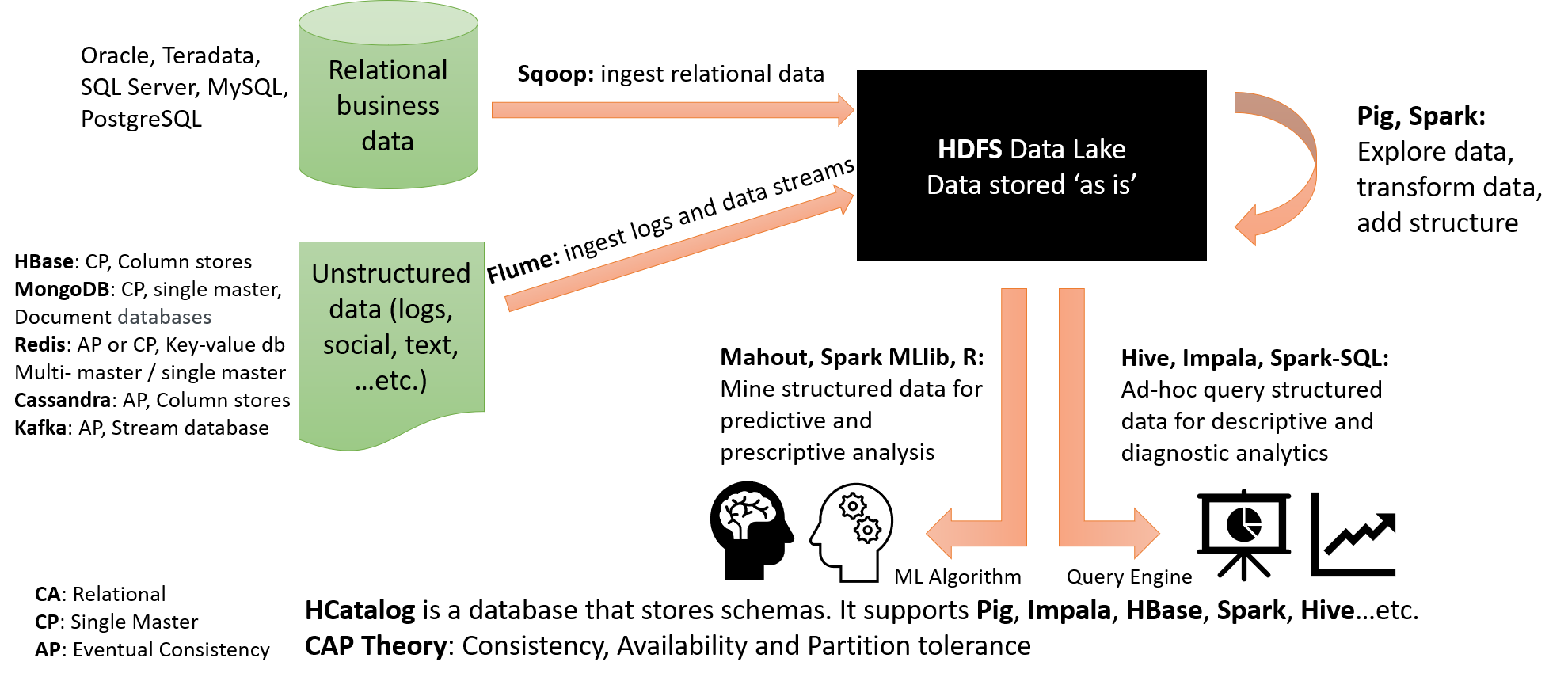
Hadoop Ecosystem in Action
Options for Data Ingestion